Enron email dataset, Information extraction, LLM, NLP, llama.cpp, Pydantic
In this post we will see how to use a local LLM to extract structured information from emails.
When I joined appliedAI Initiative in 2021, my first project involved using AI to extract information from emails for a company that develops a document management system. At that time, LLMs were not as advanced as they are today, so we decided to train a custom model from scratch. However, we faced challenges, particularly because we did not have labeled data, and due to privacy restrictions, we couldn’t use the company’s customer data. As a result, we resorted to manually labeling emails from the Enron dataset1.
Unfortunately, our approach yielded suboptimal results for several reasons, such as the mismatch between the Enron dataset and the actual customer emails and the lack of labeled training data. Today, however, extracting information from emails has become simpler than ever, and in this post, I want to demonstrate the improvements we can achieve with using LLMs.
Email information model
To start, we need define the model, and by extension the JSON schema, for the structured information we want to extract from the emails. For this, we use Pydantic to define models for email information, the sender, and the recipient, along with methods to compare and compute similarity scores.
EmailBaseModel: Base model class for email-related information extraction.
class EmailBaseModel(BaseModel, extra="forbid"):"""Base model class for email-related information extraction. This class extends BaseModel and provides common functionality for comparing string attributes between email information objects. Note: The extra="forbid" parameter ensures no additional attributes can be added beyond those explicitly defined. """@staticmethoddef _compare_strings(a: str|None, b: str|None) ->float:"""Computes similarity ratio between two possibly None strings. Uses SequenceMatcher to calculate string similarity when both inputs are not missing (None). Handles cases where one or both inputs are None. Args: a: First string to compare, or None b: Second string to compare, or None Returns: Similarity ratio between 0.0 and 1.0, where: - 1.0 indicates identical strings or both are None - 0.0 indicates completely different strings or one of them is None - Values between 0.0 and 1.0 indicate partial similarity """if a isNoneand b isNone: similarity =1.0elif a isnotNoneand b isnotNone: similarity = SequenceMatcher(None, a, b).ratio()elif a isnotNone: similarity =0.0else: similarity =0.0return similarity
Sender: Represents a sender of an email with their associated information.
class Sender(EmailBaseModel):"""Represents a sender of an email with their associated information. Stores and compares sender details including name, email, phone number, role, and organization. Attributes: name: The sender's full name if available email: The sender's email address phone_number: The sender's phone number if available role: The sender's professional role if available organization: The sender's organization if available """ name: str|None=None email: str phone_number: str|None=None role: str|None=None organization: str|None=Nonedef compare(self, other: "Sender") ->float:"""Compares this sender with another sender object. Calculates similarity by comparing all attributes using string comparison and returns the mean similarity across all fields. Args: other: Another Sender object to compare against Returns: Mean similarity ratio between 0.0 and 1.0, where: - 1.0 indicates identical senders - 0.0 indicates completely different senders or invalid comparison - Values between 0.0 and 1.0 indicate partial similarity across fields Note: Returns 0.0 if other is not a Sender instance. """ifnotisinstance(other, Sender):return0.0 name_similarity =self._compare_strings(self.name, other.name) email_similarity =self._compare_strings(self.email, other.email) phone_number_similarity =self._compare_strings(self.phone_number, other.phone_number ) role_similarity =self._compare_strings(self.role, other.role) organization_similarity =self._compare_strings(self.organization, other.organization )return fmean( [ name_similarity, email_similarity, phone_number_similarity, role_similarity, organization_similarity, ] )
Recipient: Represents a recipient of an email with their associated information.
class Recipient(EmailBaseModel):"""Represents a recipient of an email with their associated information. Stores and compares recipient details including name, email, phone number, role, organization, and their type of recipiency (to, cc, bcc). Attributes: name: The recipient's full name if available email: The recipient's email address phone_number: The recipient's phone number if available role: The recipient's professional role if available organization: The recipient's organization if available type: The type of recipient ("to", "cc", or "bcc") """ name: str|None=None email: str phone_number: str|None=None role: str|None=None organization: str|None=Nonetype: Literal["to", "cc", "bcc"] ="to"def compare(self, other: "Recipient") ->float:"""Compares this recipient with another recipient object. Calculates similarity by comparing all attributes using string comparison and includes exact matching for recipient type. Returns the mean similarity across all fields. Args: other: Another Recipient object to compare against Returns: Mean similarity ratio between 0.0 and 1.0, where: - 1.0 indicates identical recipients - 0.0 indicates completely different recipients or invalid comparison - Values between 0.0 and 1.0 indicate partial similarity across fields Note: Returns 0.0 if other is not a Recipient instance. Recipient type comparison is binary: 1.0 if identical, 0.0 if different. """ifnotisinstance(other, Recipient):return0.0 name_similarity =self._compare_strings(self.name, other.name) email_similarity =self._compare_strings(self.email, other.email) phone_number_similarity =self._compare_strings(self.phone_number, other.phone_number ) role_similarity =self._compare_strings(self.role, other.role) organization_similarity =self._compare_strings(self.organization, other.organization ) type_similarity =1.0ifself.type== other.typeelse0.0return fmean( [ name_similarity, email_similarity, phone_number_similarity, role_similarity, organization_similarity, type_similarity, ] )
EmailInformation: Represents information extracted from an email.
class EmailInformation(EmailBaseModel):"""Represents information extracted from an email. Stores and compares email metadata including date, subject, sender information, and a list of recipients. Provides functionality to compare two email information objects for similarity. Attributes: date: The date of the email subject: The email subject line sender: Sender object containing sender information recipients: List of Recipient objects containing recipient information """ date: str subject: str sender: Sender recipients: list[Recipient]def compare(self, other: "EmailInformation") ->float:"""Compares this email information with another email information object. Performs a detailed comparison of all email attributes including sender and recipient information. For recipients, finds the best matching recipient pairs between the two emails and averages their similarities. Args: other: Another EmailInformation object to compare against Returns: Mean similarity ratio between 0.0 and 1.0, where: - 1.0 indicates identical email information - 0.0 indicates completely different emails or invalid comparison - Values between 0.0 and 1.0 indicate partial similarity across all fields Note: - Returns 0.0 if other is not an EmailInformation instance. - Returns 1.0 if self == other (exact match). - Recipient comparison finds the best matching recipient for each recipient in self.recipients among other.recipients. """ifnotisinstance(other, EmailInformation):return0.0ifself== other:return1.0 date_similarity =self._compare_strings(self.date, other.date) subject_similarity =self._compare_strings(self.subject, other.subject) sender_similarity =self.sender.compare(other.sender)ifself.recipients == other.recipients: recipient_similarity =1.0else: recipient_similarities = []for recipient_1 inself.recipients: recipient_1_similarity =0.0for recipient_2 in other.recipients: recipient_1_similarity =max( recipient_1_similarity, recipient_1.compare(recipient_2) ) recipient_similarities.append(recipient_1_similarity)if recipient_similarities: recipient_similarity = fmean(recipient_similarities)else: recipient_similarity =0.0return fmean( [ date_similarity, subject_similarity, sender_similarity, recipient_similarity, ] )
To evaluate our approaches, we define a helper function to run the extraction on all emails in a given dataset and compute similarities.
evaluate_extraction: Function that evaluates an email information extraction function against a ground truth dataset.
def evaluate_extraction( extract_fn: Callable[[str], EmailInformation], dataset: list[dict[str, Any]],) ->list[float]:"""Evaluates an email information extraction function against a ground truth dataset. Processes each email in the dataset using the provided extraction function and compares the results against ground truth annotations using the EmailInformation comparison logic. Args: extract_fn: Function that takes a raw email string as input and returns an EmailInformation object containing the extracted information. dataset: List of dictionaries, where each dictionary contains: - 'raw_email': The raw email text to process - 'extracted_information': Ground truth EmailInformation object Returns: List of similarity scores between 0.0 and 1.0 for each email, where: - 1.0 indicates perfect extraction matching ground truth - 0.0 indicates completely incorrect extraction - Values between indicate partial matching of extracted information """ scores = []for sample in tqdm(dataset, desc="Emails", leave=False): extracted_information = extract_fn(sample["raw_email"]) score = sample["extracted_information"].compare(extracted_information) scores.append(score)return scores
Data
For this exercise, we use 20 emails from the Enron dataset that I labelled myself. We use 4 emails for the training set ( We will see later for what purpose we need such as set) and 16 emails for the test set.
Sample raw email:
Message-ID: <23530825.1075858413552.JavaMail.evans@thyme>Date: Thu, 10 May 2001 05:08:00 -0700 (PDT)From: kam.keiser@enron.comTo: sabra.dinari@enron.comSubject: FP&LCc: yuan.tian@enron.com, scott.neal@enron.comMime-Version:1.0Content-Type: text/plain; charset=us-asciiContent-Transfer-Encoding: 7bitBcc: yuan.tian@enron.com, scott.neal@enron.comX-From: Kam KeiserX-To: Sabra L DinariX-cc: Yuan Tian, Scott NealX-bcc:X-Folder: \Scott_Neal_Jun2001\Notes Folders\Notes inboxX-Origin: Neal-SX-FileName: sneal.nsfSabra,I have extended the current FP&L sitara #217969 to the end of the deal(2/2010).Keeping the same deal # helps us keep up with the value.I set it up with the volumes we booked in TAGG, I know the volumes andlocations will change but if you could send me and Yuan an e-mail when youhave made your change during bid week we will make the changes to the hedgedeal.Thanks,Kamps. Scott, you will not see any problems with this deal in the future.Sorry for the trouble.
As a baseline, we use Python’s built-in email parser from the email package to extract information. We define an extraction function that parses the emails and extracts basic information without much validation.
extract_information_with_builtin_parser: Function that extracts information using Python’s built-in email parser.
def extract_information_with_builtin_parser(raw_email: str) -> EmailInformation:"""Extracts structured information from a raw email using Python's built-in email parser. Parses the raw email text to extract metadata including date, subject, sender, and recipients. Handles special X-headers for additional information like sender and recipient names. Args: raw_email: Raw email text including headers and body. Returns: Structured object containing the extracted information with: - date: Formatted as DD.MM.YYYY - subject: Email subject line - sender: Sender information including email and optional name - recipients: List of recipients (to/cc/bcc) with email and optional name, sorted by email address """ parser = Parser() email = parser.parsestr(raw_email) parsed_date = datetime.strptime( email["date"].strip().split("(")[0], "%a, %d %b %Y %H:%M:%S %z " ) formatted_date = parsed_date.strftime("%d.%m.%Y") email_dict = {"date": formatted_date, "subject": email["subject"].strip()} sender = {"email": email["from"].strip()}if email["X-from"] and email["X-from"].strip() != email["from"]: sender["name"] = email["X-from"].strip() email_dict["sender"] = sender recipients = []for type_ in ["to", "cc", "bcc"]: recipient_names = email.get(f"X-{type_}", "").strip().split(",") recipient_emails = email.get(type_, None)if recipient_emails isNone:continue recipient_emails = recipient_emails.split(",")iflen(recipient_emails) !=len(recipient_names): recipient_names = [""] *len(recipient_emails)for recipient_name, recipient_email inzip(recipient_names, recipient_emails): recipient = {"type": type_, "email": recipient_email.strip()}if recipient_name and recipient_name != recipient_email: recipient["name"] = recipient_name.strip() recipients.append(recipient) email_dict["recipients"] =list(sorted(recipients, key=lambda x: x["email"]))return EmailInformation.model_validate(email_dict)
Using this method, we extract the following information from the sample test email:
{"date":"10.05.2001","subject":"FP&L","sender":{"name":"Kam Keiser","email":"kam.keiser@enron.com","phone_number":null,"role":null,"organization":null},"recipients":[{"name":"Sabra L Dinari","email":"sabra.dinari@enron.com","phone_number":null,"role":null,"organization":null,"type":"to"},{"name":"Scott Neal","email":"scott.neal@enron.com","phone_number":null,"role":null,"organization":null,"type":"cc"},{"name":null,"email":"scott.neal@enron.com","phone_number":null,"role":null,"organization":null,"type":"bcc"},{"name":"Yuan Tian","email":"yuan.tian@enron.com","phone_number":null,"role":null,"organization":null,"type":"cc"},{"name":null,"email":"yuan.tian@enron.com","phone_number":null,"role":null,"organization":null,"type":"bcc"}]}"
We also compute the average score of this approach on the test set:
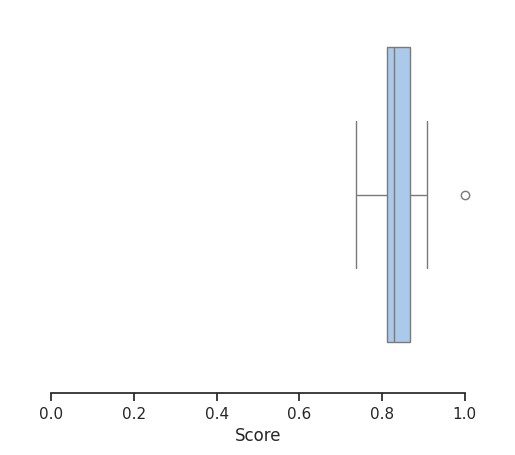
84.29%
The results are plotted as a box plot, showing that while the extraction is relatively good, it is far from perfect.
Builtin Email Parser Score
First Approach - Use LLM zero-shot extraction with JSON schema
Next, we explore using an LLM for zero-shot extraction with a JSON schema. For this, we use llama-cpp-python, a Python wrapper for llama.cpp, to run a local LLM. This approach allows us to pass a JSON schema, ensuring structured output without needing to adjust the prompt repeatedly in order to coerce the LLM into generating valid JSON data.
Note: There are known performance issues with llama.cpp’s structured output generation using grammars and, by extension, json schemas especially with nested objects.
We use a quantized version of Llama 3.2 3B Instruct with a context length of 16,384 tokens to handle long raw emails.
A system prompt is defined to guide the LLM, using a JSON type definition instead of a JSON schema, inspired by a blog post I came across. This version is shorter, produces better results, and is more human-readable.
We then define a system prompt to guide the LLM, using a JSON type definition instead of a JSON schema, inspired by this blog post I came accross. The prompt with the type definition is shorter, produces better results and is more human-readable.
extract_information_with_llm: Function that extracts information using an LLM
def extract_information_with_llm( raw_email: str, *, system_prompt: str) -> EmailInformation:"""Extracts structured information from a raw email using an LLM. Uses chat completion API to parse email content into structured format. Enforces output schema validation using EmailInformation model specification. Args: raw_email: Raw email text including headers and body. system_prompt: System prompt for the LLM that defines the extraction task. Returns: Structured object containing the extracted information, validated against the EmailInformation schema. """ response_format = {"type": "json_object","schema": EmailInformation.model_json_schema(), } output = llm.create_chat_completion_openai_v1( messages=[ {"role": "system","content": system_prompt, }, {"role": "user", "content": raw_email}, ], response_format=response_format, temperature=0.3, ) extracted_information = EmailInformation.model_validate_json( output.choices[0].message.content )return extracted_information
Using this method, we extract the following information from the sample test email:
Sample extracted information with llm zero-shot prompt:
{"date":"Thu, 10 May 2001 05:08:00 -0700 (PDT)","subject":"FP&L","sender":{"name":"Kam Keiser","email":"kam.keiser@enron.com","phone_number":null,"role":"X-From","organization":"X-Origin: Neal-S"},"recipients":[{"name":"Sabra L Dinari","email":"sabra.dinari@enron.com","phone_number":null,"role":"X-To","organization":"X-Origin: Neal-S","type":"to"},{"name":"Yuan Tian","email":"yuan.tian@enron.com","phone_number":null,"role":"X-cc","organization":"X-Origin: Neal-S","type":"cc"},{"name":"Scott Neal","email":"scott.neal@enron.com","phone_number":null,"role":"X-cc","organization":"X-Origin: Neal-S","type":"cc"}]}"
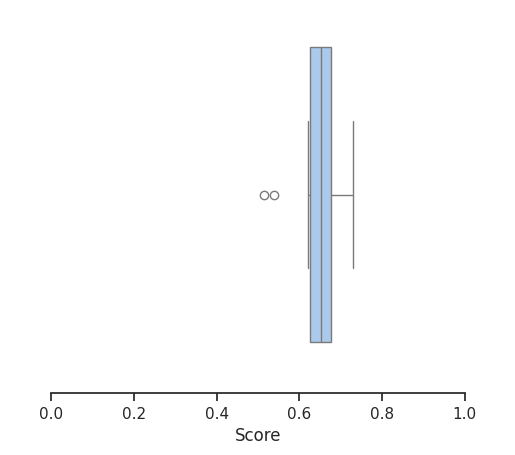
We also compute the average score of this approach on the test set:
64.55%
LLM Zero-Shot Prompt Score
We can see that this approach performs much worse than the previous one, most likely due to mismatch in expected formats. For example, we expected the date to be of the form 11.07.2001 instead of 11/07/2001, 11 Jul 2001 or Wed, 11 Jul 2001.
To fix that, we will provide an example of information extraction in the system prompt in order to better guide the LLM.
Second approach - LLM few-shot extraction with JSON schema
To improve performance, we move to a few-shot approach. Given context length and performance constraints, we use one example from the training set in the system prompt, making it a one-shot prompt approach.
We evaluate the impact of each example from the training set on the remaining examples in the training set to determine which one best improves the information extraction.
Code
score_improvements = []for i in trange(len(train_set), desc="Example"): example = train_set[i] train_set_without_example = train_set[:i] + train_set[i +1 :]# We first compute the similarity with the zero-shot system prompt scores_zero_shot = evaluate_extraction( partial(extract_information_with_llm, system_prompt=system_prompt), train_set_without_example, ) mean_score_zero_shot = np.mean(scores_zero_shot).item()# We then compute the similarity with the one-shot (with example) system prompt system_prompt_with_example = ( system_prompt+f"""Use the following example of raw email and extracted information as reference:# Raw email{example["raw_email"]}# Extracted information{example["extracted_information"].model_dump_json(indent=2)}""" ) scores_one_shot = evaluate_extraction( partial(extract_information_with_llm, system_prompt=system_prompt_with_example), train_set_without_example, ) mean_score_one_shot = np.mean(scores_one_shot).item()# We then compute the difference in similarity score_improvement = mean_score_one_shot - mean_score_zero_shot score_improvements.append( ( score_improvement, system_prompt_with_example, ) )
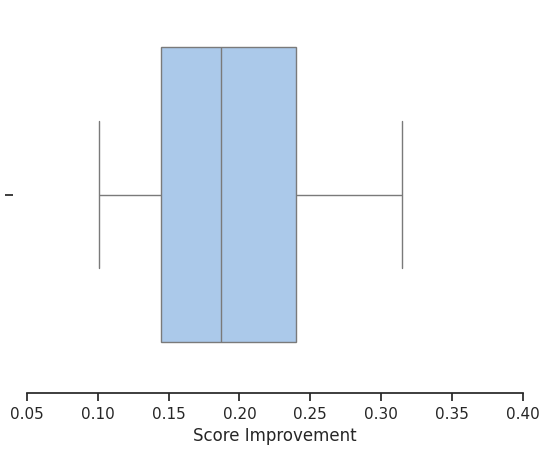
LLM One-Shot Prompt Score Improvement
The best score improvement we can obtain using the one-shot prompt and out small train set is: 31.45
The system prompt and, by extension, example corresponding to this improvement are:
YouareahelpfulassistantthatextractinformationfromauserprovidedemailinJSONformatthatadherestothefollowingschema:{"date":string,"subject":string,"sender":{"name":string|null,"email":string,"phone_number":string|null,"role":string|null,"organization":string|null},"recipients":{"name":string|null,"email":string,"phone_number":string|null,"role":string|null,"organization":string|null,"to":enum(["to","cc","bcc"])}[]}Usethefollowingexampleofrawemailandextractedinformationasreference:#RawemailMessage-ID:<7555575.1075857946274.JavaMail.evans@thyme>Date:Mon,30Apr200111:17:00-0700(PDT)From:cathy@pira.comTo:greg@pira.comSubject:PIRA'sSpecialReleaseGasFlash:StrongSupplyGrowthIndicated04/30/01Mime-Version:1.0Content-Type:text/plain;charset=us-asciiContent-Transfer-Encoding:7bitX-From:"Cathy Lopez"<cathy@pira.com>X-To:"PIRA Natural Gas Retainer Client"<greg@pira.com>X-cc:X-bcc:X-Folder:\Lawrence_May_Jun2001_1\NotesFolders\NotesinboxX-Origin:May-LX-FileName:lmay2.nsfAttachedisaPIRASpecialReleaseentitled"Gas Flash: Strong Supply GrowthIndicated."Ifyouhaveanyquestionsregardingthereport'scontent,pleasecontact:GregShuttlesworth(email:greg@pira.com),TomHoward(email:tazh@pira.com),RichardRedash(email:Rich@pira.com),NobuTarui(email:nobuo@pira.com)orJaneHsu(email:jane@pira.com),at(212)686-6808.ContactJohnGrazianoregardingPIRAreportdistributionandaddresschangesat(212)686-6808,email:support@pira.com.NOTE:Circulationofthe"Gas Flash Weekly"outsideaClient'slicenseddistributionareaisstrictlyprohibited.ClientsthatareunsureoftheirlicenseddistributionorrequireanextensionoftheircurrentlicenseshouldcontacttheirPIRAsalesrepresentative,oremailtosales@pira.com.PIRAEnergyGroup-agaspec043001.pdf#Extractedinformation{"date":"30.04.2001","subject":"PIRA's Special Release Gas Flash: Strong Supply Growth Indicated 04/30/01","sender":{"name":"Cathy Lopez","email":"cathy@pira.com","phone_number":null,"role":null,"organization":"PIRA Energy Group"},"recipients":[{"name":"Greg Shuttlesworth","email":"greg@pira.com","phone_number":null,"role":null,"organization":"PIRA Energy Group","type":"to"}]}
Using this method, we extract the following information from the sample test email:
Sample extracted information with llm one-shot prompt:
{"date":"10.05.2001","subject":"FP&L","sender":{"name":"Kam Keiser","email":"kam.keiser@enron.com","phone_number":null,"role":null,"organization":"Enron"},"recipients":[{"name":"Sabra L Dinari","email":"sabra.dinari@enron.com","phone_number":null,"role":null,"organization":"Enron","type":"to"},{"name":"Yuan Tian","email":"yuan.tian@enron.com","phone_number":null,"role":null,"organization":"Enron","type":"cc"},{"name":"Scott Neal","email":"scott.neal@enron.com","phone_number":null,"role":null,"organization":"Enron","type":"cc"}]}"
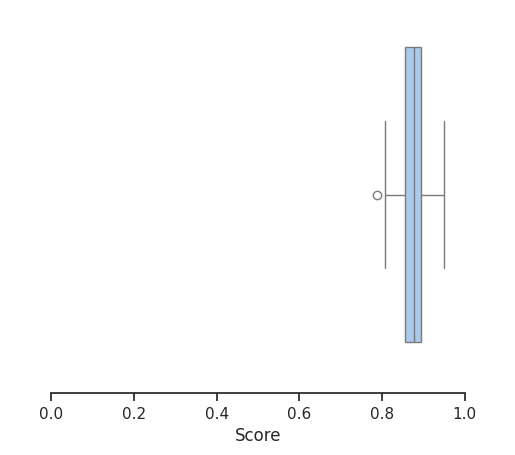
The average score of this second approach on the test set is:
87.27%
LLM One-Shot Prompt Score
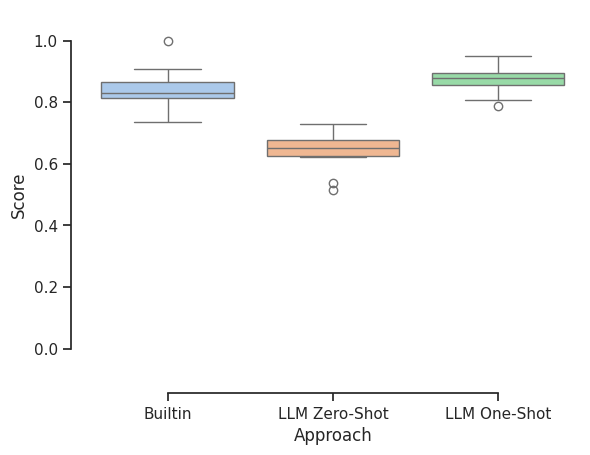
Comparison of the 3 approaches
When comparing the scores of the three approaches, it is clear that both the baseline parser and the few-shot approach outperform the zero-shot approach. The few-shot approach is more flexible and generalizes better, which could prove beneficial when scaling to larger datasets.
LLM One-Shot Prompt Score
Conclusion
In this post, we have seen how a local LLM can be used to extract structured information from emails, provided you have access to the email content and the necessary permissions. We also explored how adding an example to the system prompt (few-shot prompting) can significantly improve the extraction.
This post is intended as a demonstration of how structured information extraction can be done with modern LLMs. For real-world applications, however, you would likely face additional constraints, such as more complex datasets, stricter privacy considerations, and the need for larger datasets to improve accuracy and robustness.
Footnotes
Enron Corporation was an American energy, commodities, and services that went bankrupt in 2001 after ascandal involving a corporate fraud case. The Enron Email Dataset, containing 500,000 internal emails, provides valuable insights into the company’s operations and is widely used for research in text mining and network analysis.↩︎